Die häufigste Frage, die wir hören, bevor ein KI-Projekt startet: "Wer haftet, wenn die KI einen Fehler macht?" Die Frage ist berechtigt. Aber sie führt in die falsche Richtung, wenn sie als Grund dient, gar nicht erst anzufangen.
Die bessere Frage lautet: Wie mache ich das Risiko messbar und kontrollierbar? Denn genau das ist möglich. Nicht durch Hoffen auf Fehlerfreiheit, sondern durch Methoden, die das Risiko quantifizieren, kategorisieren und auf ein akzeptables Maß reduzieren.
Kontrollierte Autonomie statt blindes Vertrauen
Der Schlüssel liegt in einer einfachen Unterscheidung: Nicht jede Entscheidung hat das gleiche Risiko. Eine falsch zugeordnete Produktkategorie ist ärgerlich, aber korrigierbar. Eine falsche Rechtsauskunft an einen Endkunden ist ein ernstes Problem. Beides mit dem gleichen Sicherheitsniveau zu behandeln, wäre entweder fahrlässig oder blockierend.
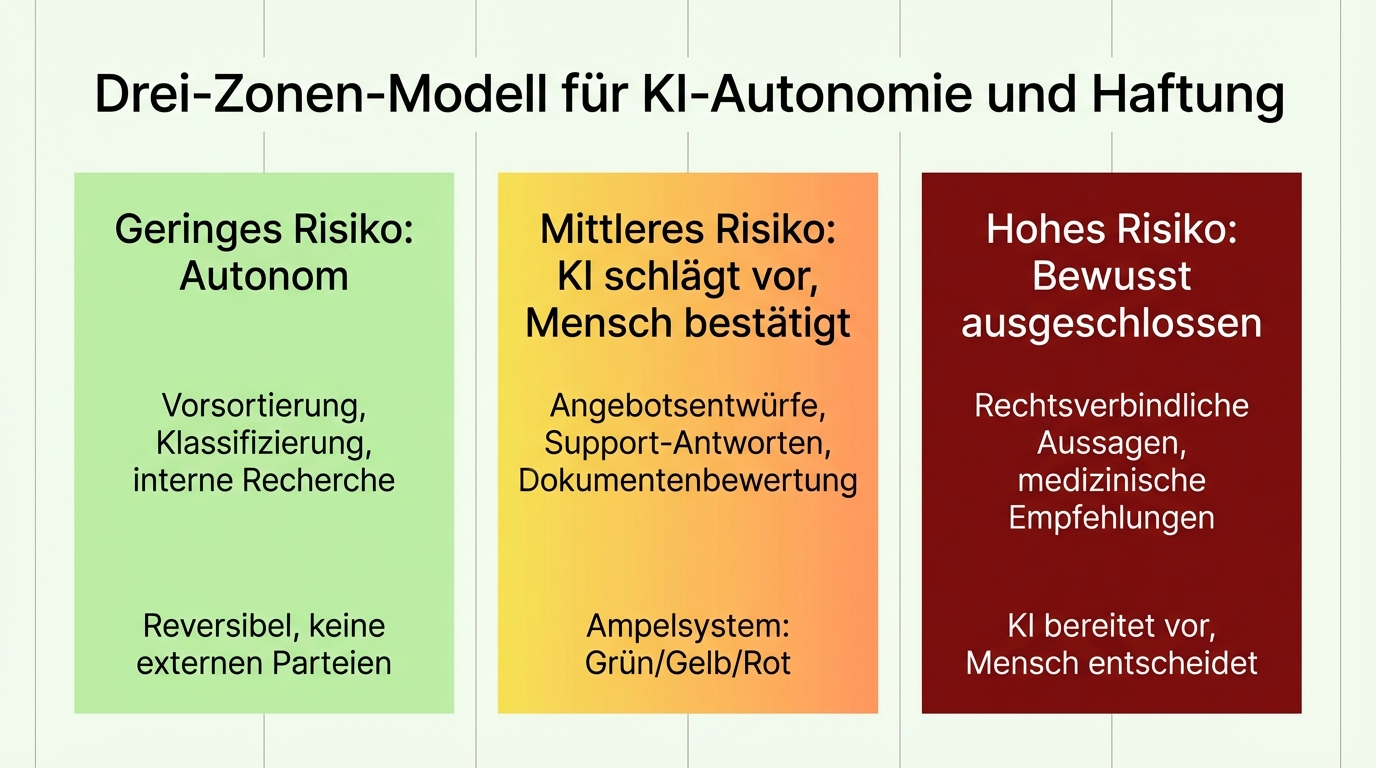
Deshalb bewerten wir jede Anfragekategorie einzeln, gemeinsam mit den Fachexperten des Kunden, nach dem Kriterium: Was ist das Schlimmste, das passieren kann? Daraus ergeben sich drei Zonen:
Geringes Risiko: Autonom. Die KI entscheidet und handelt selbstständig. Typisch für Vorsortierung, Klassifizierung, interne Recherche. Wenn ein Fehler passiert, ist er reversibel und betrifft keine externen Parteien.
Mittleres Risiko: KI schlägt vor, Mensch bestätigt. Das Ampelsystem: Grün bedeutet, der Mensch kann direkt übernehmen. Gelb bedeutet, der Mensch sollte genauer hinschauen. Rot bedeutet, der Mensch muss von vorne anfangen. So werden aus tausenden Vorgängen vielleicht hundert, die wirklich menschliche Aufmerksamkeit brauchen.
Hohes Risiko: Bewusst ausgeschlossen. Manche Entscheidungen bleiben beim Menschen. Rechtsverbindliche Aussagen, medizinische Empfehlungen, sicherheitskritische Freigaben. Der Wert der KI liegt hier nicht in der Entscheidung, sondern in der Vorbereitung: Informationen zusammentragen, Optionen strukturieren, Entwürfe erstellen.
Ein konkretes Beispiel: Bei einem automatisierten Kundensupport-System haben wir mit 400 realen Anfragen trainiert, welche Kategorien autonom beantwortet werden dürfen und welche nicht. Die Kriterien: kein Datenverlust, kein Datenschutzvorfall, keine unberechtigte Informationsweitergabe. Was die KI nicht sicher zuordnen kann, wird an einen Menschen eskaliert.
Das Risiko messen, nicht raten
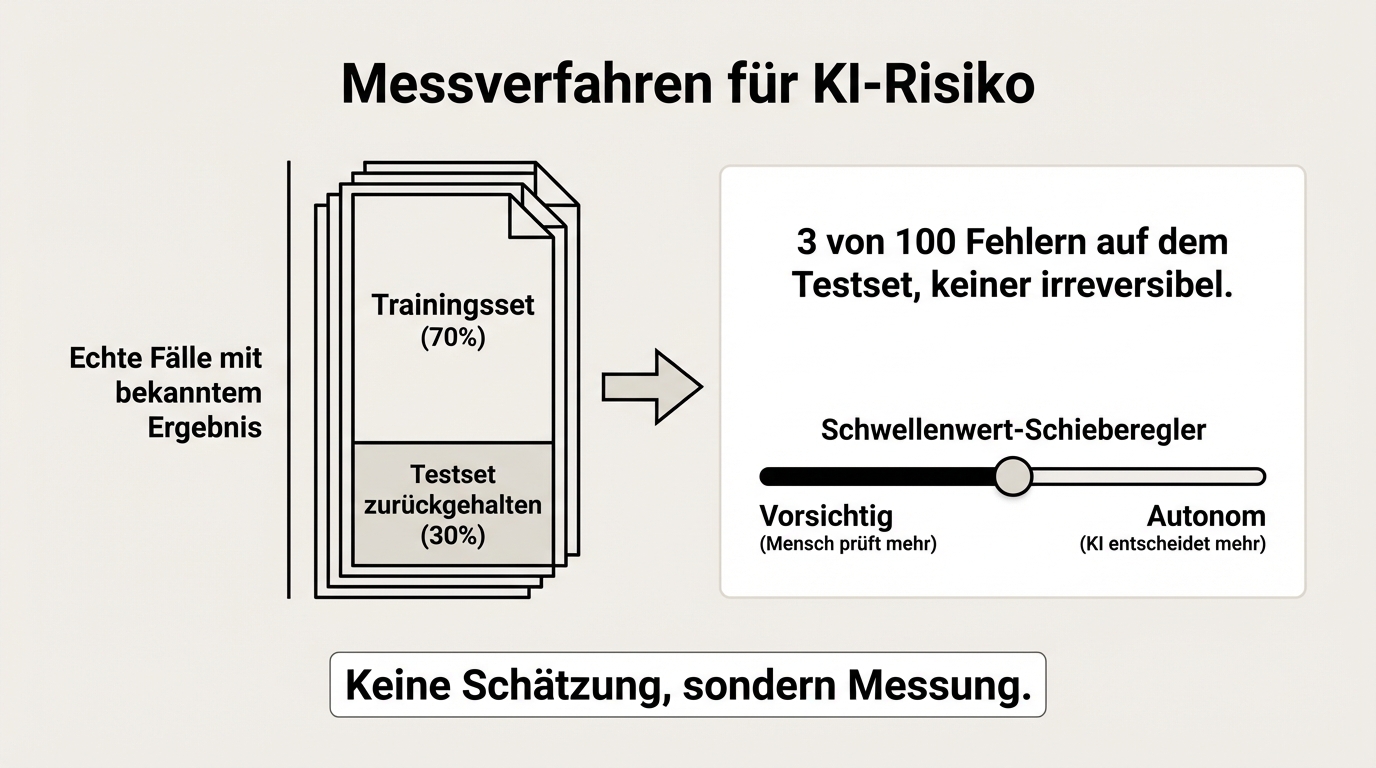
"Die KI macht manchmal Fehler" ist keine nützliche Aussage. Nützlich ist: "Die KI macht bei diesem Dokumententyp in 3 von 100 Fällen einen Fehler, und in keinem dieser Fälle ist der Fehler irreversibel."
Genau diese Aussage können wir treffen. Für jeden Anwendungsfall bauen wir einen Referenzdatensatz auf: echte Fälle, bei denen das richtige Ergebnis bekannt ist. Ein Teil davon wird zum Training verwendet, ein Teil zurückgehalten. Auf dem zurückgehaltenen Teil messen wir die Fehlerrate, bevor das System live geht. Das Ergebnis ist keine Schätzung, sondern eine Messung.
Das bedeutet auch: Wir können objektiv angeben, bei welchem Schwellenwert das System autonom entscheiden darf und ab wann ein Mensch eingreifen muss. Der Schwellenwert wird so gesetzt, dass keine teuren Fehler passieren. Lieber zu vorsichtig als zu aggressiv.
Diese Methodik ist nicht neu. Sie entspricht dem, was in der klassischen Qualitätssicherung seit Jahrzehnten praktiziert wird: Stichprobenprüfung, Konfidenzintervalle, definierte Fehlertoleranzen. Nur dass die Prüfung jetzt automatisiert stattfindet, auf jedem einzelnen Vorgang, nicht nur auf einer Stichprobe.
Von "immer prüfen" zu "kontrolliert vertrauen"
Am Anfang steht der Parallelbetrieb. Die KI erstellt einen Entwurf, der Mensch prüft jedes Ergebnis, korrigiert wo nötig und gibt frei. Das ist die Einführungsphase, in der das System lernt und der Mensch Vertrauen aufbaut.
"Die ersten zwei Monate habe ich nervös geschlafen", sagt ein Projektleiter über den ersten vollautonomen Kundenservice-Bot. "Jeden Tag auf die Ergebnisse geschaut. Irgendwann gemerkt: Es funktioniert." Diese ehrliche Nervosität ist kein Zeichen von Schwäche, sondern von Verantwortungsbewusstsein. Wer nicht nervös ist, hat die Tragweite nicht verstanden.
Nach der Einführungsphase kann sich das Vertrauen schrittweise erweitern, datengestützt. Wenn über Wochen hinweg die Übereinstimmung zwischen KI-Ergebnis und menschlicher Korrektur steigt, kann man den Schwellenwert für autonome Entscheidungen anheben. Nicht weil man hofft, dass es funktioniert, sondern weil man es gemessen hat.
Das Ziel ist nicht, den Menschen komplett zu ersetzen. Es ist, den Menschen dort einzusetzen, wo er wirklich gebraucht wird: bei den schwierigen Fällen, bei den Ausnahmen, bei den Entscheidungen, die Urteilsvermögen erfordern. Nicht bei der Routine, die 80 Prozent des Tages frisst.
Wer haftet? Eine klare Aufteilung
Die Verantwortung verteilt sich auf drei Ebenen:
Technische und inhaltliche Verantwortung: Beim Dienstleister. Wir stellen sicher, dass das System korrekt arbeitet, die Quellen aktuell sind, die Schwellenwerte richtig gesetzt sind und die Qualitätssicherung greift. Wenn ein Fehler auf unsere Arbeit zurückzuführen ist, tragen wir die Konsequenzen.
Rechtliche Verantwortung: Beim Kunden. Der Kunde entscheidet, welche Ergebnisse er nutzt, freigibt und nach außen kommuniziert. Die KI informiert, empfiehlt, bereitet vor. Die Entscheidung, ob und wie ein Ergebnis verwendet wird, bleibt beim Menschen.
Qualitätszusage: Messbar und nachvollziehbar. Jede KI-Generierung hinterlässt eine vollständige Spur: welcher Prompt wurde verwendet, welche Quellen herangezogen, welche Entscheidung das Modell getroffen hat. Wenn etwas schiefgeht, lässt sich die Ursache in der Regel innerhalb von Stunden identifizieren. Erfahrungsgemäß liegt sie zur Hälfte am Prompt, zur Hälfte an den Quellen, fast nie an der Technologie selbst.
Diese Aufteilung ist kein Kleingedrucktes, sondern eine bewusste Architekturentscheidung. Sie stellt sicher, dass die technische Qualität messbar ist, die geschäftliche Entscheidung beim Menschen bleibt und beide Seiten wissen, wofür sie verantwortlich sind.
Der richtige Vergleichsmaßstab
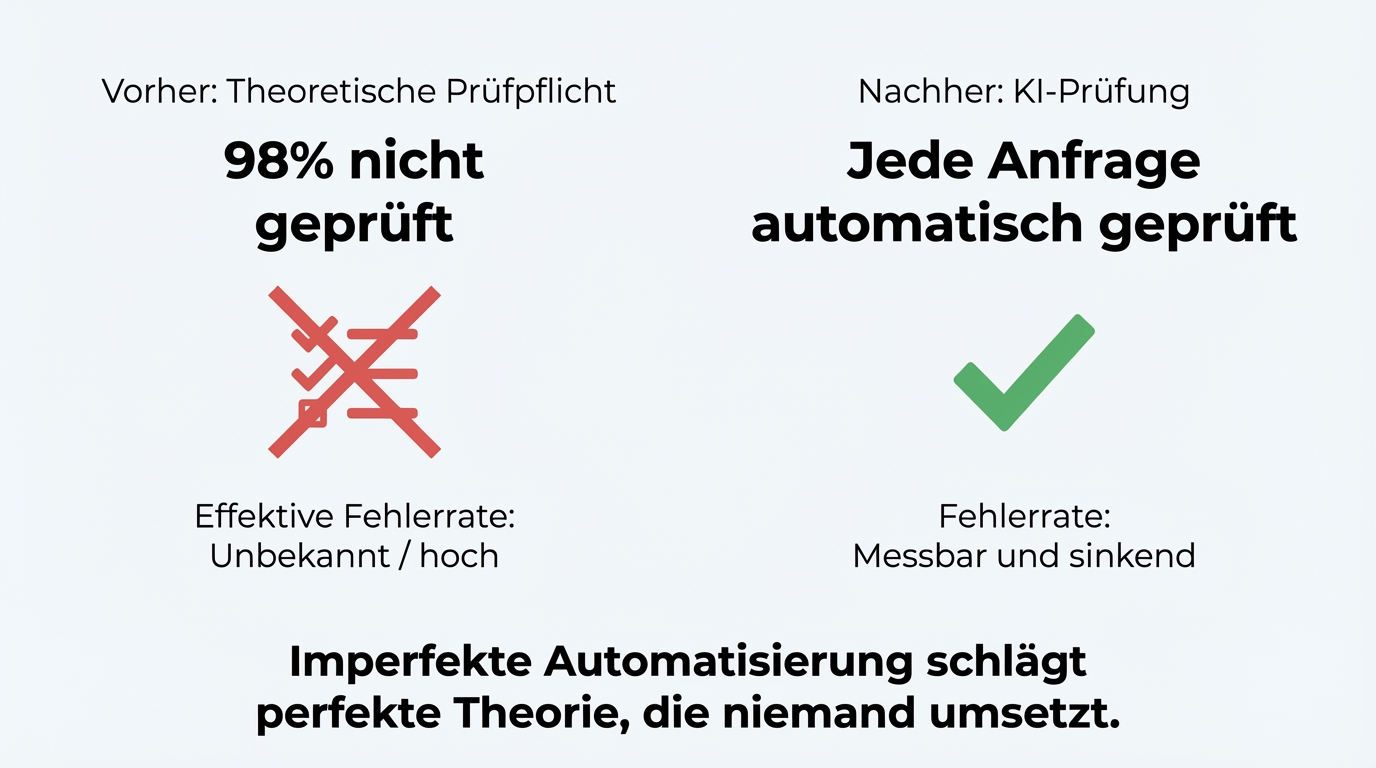
Die meisten Diskussionen über KI-Haftung vergleichen die KI mit Perfektion. Der richtige Vergleich ist ein anderer: Die KI gegen den aktuellen Prozess.
Bei einem Unternehmen wurden Anfragen auf Vollständigkeit geprüft, bevor sie bearbeitet wurden. In der Theorie. In der Praxis wurde die Prüfung in 98 Prozent der Fälle nicht gemacht. "Dauert zwei Minuten, aber die Kollegen machen es trotzdem nicht." Jetzt prüft die KI automatisch jede Anfrage. Ja, sie macht gelegentlich Fehler. Aber selbst mit einer Fehlerrate von 2 Prozent ist das System dramatisch besser als der Ausgangszustand: keine Prüfung.
Wenn die Frage lautet "Ist die KI perfekt?", lautet die Antwort nein. Wenn die Frage lautet "Ist der Prozess mit KI besser als ohne?", lautet die Antwort in allen Projekten, die wir gesehen haben: eindeutig ja.